So as I was stepping out of my apartment last week, I thought in california I really don’t care about the temperature outside, all I want to know is if it is cold enough to wear a jacket or warm enough not to. I decided to build a weather based decision engine which does just that, figure out where I am, check the temperature and give me a decision. I also wanted it to be blazing fast and scalable.
The end result was http://wearthejacket.com/[Update:shutting this service down today on October 9th 2014, after almost an year of 100% uptime. This was a fantastic learning experience]
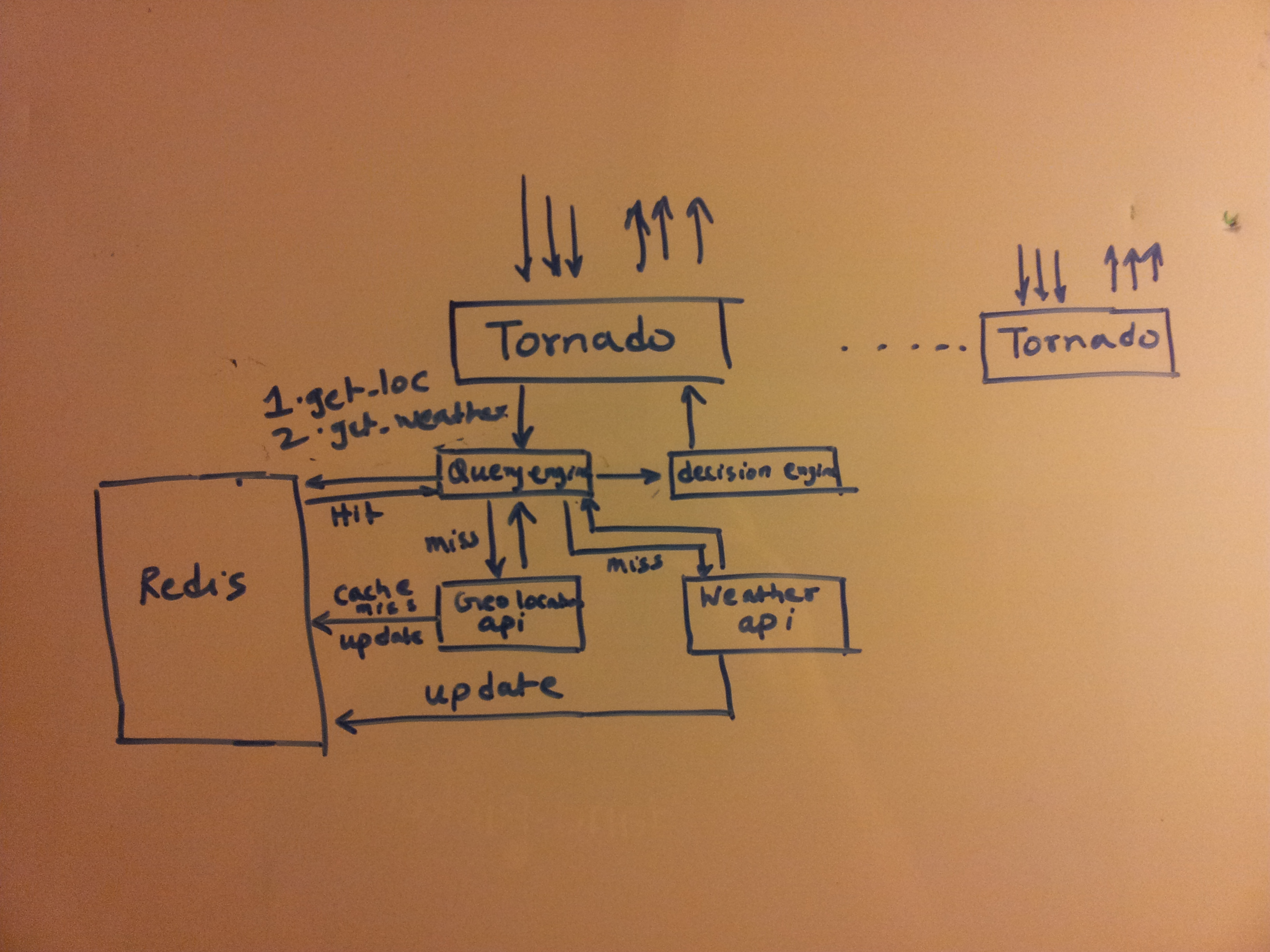
The first step was to think how I could achieve this. After some thought I came up with this sketch.

architecture
I was aware of existing geolocation api’s which translate an IP address to a location. That led me to
http://freegeoip.net/, which is a great api for a project like this with access to 10000 api calls per hour before getting throttled. This was more than sufficient for my needs.
The other component was getting the weather information. After googling for a bit, I came across forecast.io which though being a robust api had a free cap of 1000 calls per day and a nominal payment after that.
The hosting was on a AWS(Amazon web services) small ubuntu linux instance.
I decided to use tornado over apache mainly due to its low memory consumption during idle time and since I was going to write this in python. The decision to use Redis was a simple one as I would definitely need to cache some values as the end user requests came in.
This was the first pass I wrote.
1. User comes to webserver,
2. webserver queries geolocation api and obtains end users coordinates and location.
3. Based on the coordinates we query a weather api and
4. Finally take a decision based on the prevailing temperature. The decision algorithm being very simple based on a pre-set threshold below which wearing a jacket is advised. This is a todo for future enhancement.
Note that I had not written the caching mechanism yet. There lies the fun part. At this point the decision was taking well over 1 second. Certainly not acceptable for a public facing web application.
Enter Redis. Redis is an in-memory key-value data store. That makes lookups blazing fast. The first thing that I needed to do was to cache the location information that we pulled from the geo-location api . The location information that the application needed were the latitude, longitude and actual city name. This made it a good candidate for the usage of a Redis Hash.
So the first mapping was
HMSET IP location val latitude val longitude val
Since this data will not change rapidly even with dynamic ips we can keep these mappings forever and over time as user queries come in build our own database of ip’s to locations.
For the weather information, I made an assumption that weather conditions will be similar over 10 mins at a given location[debatable, but will fulfill most needs.]
This is a simple redis key value pair location:apparentTemperature the only caveat being we want it to expire every 10 minutes(configurable).
This is done easily in Redis via the setex command, with the invocation
SETEX key <expiration_time_in_seconds> value.
Once the cache mechanism was in place the benchmarking showed dramatic improvements. Sub 30 ms response times after the first api call was made. The first api call to the application though was still remarkably slow. Then I started looking at individual api calls to the external services.
There lied the answer, the forecast.io api was spewing out an entire days worth of data.
The fix was to append the forecast.io api call with
?exclude=minutely,hourly,daily,alerts,flags
which had the effect of only giving back the current prevailing conditions.
Once this was done came the part to write tests. Not true Test driven development but I was’t launching without baseline tests. This part took me the longest time but greatly increased confidence in the code for launch. As of now it has run for over a day serving requests across the globe. Always write tests, preferably before even the first line of code.
Benchmarking after that indicated a theoretical capacity of 1.5 million requests/ day. Not bad for a tiny server, and the best part is that it can be horizontally scaled.[though I doubt I will do that considering it takes $$$ to keep servers running.]
The components are modular so that you use individual components. Would love to know your thoughts on how this project can be enhanced and or design decisions that you would make.
One more thing
Building this has been a great learning experience and to enable others to learn/critique
The source code is released under the GPLV3 license.
https://github.com/hvd/wearthejacket_oss